
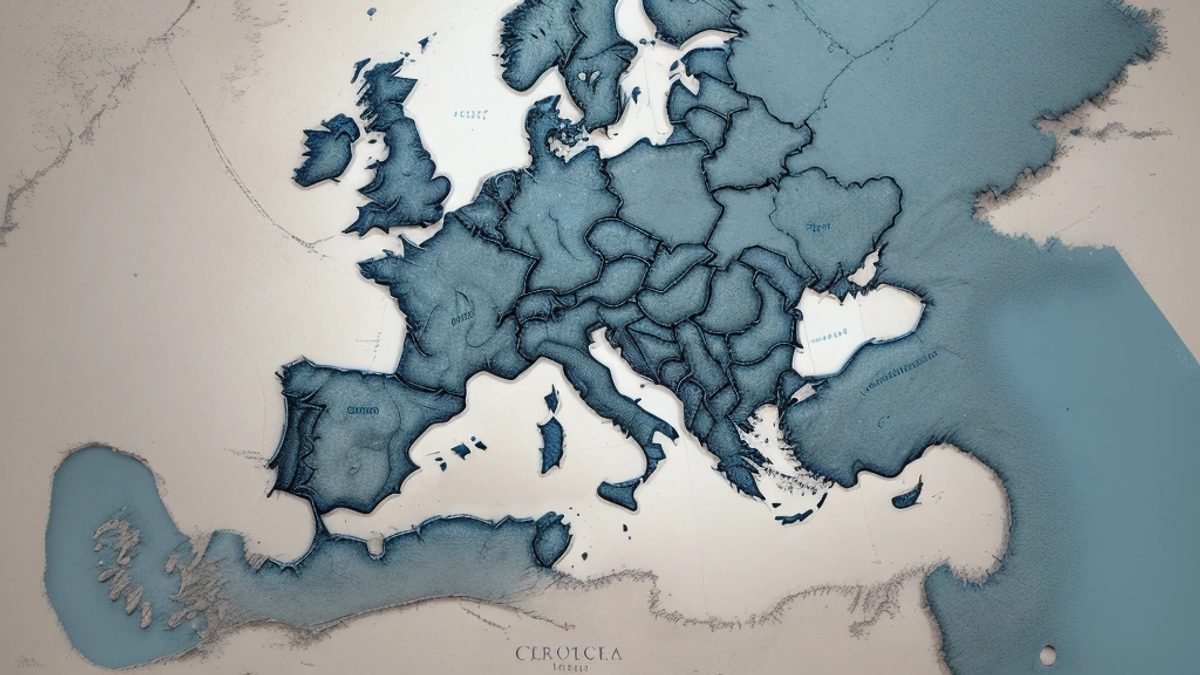

A viral prompt questioning Google’s Gemini Pro to generate a map of Europe has exposed a painful tension at the heart of modern AI development: when safety filters become so aggressive they undermine basic factual utility.
Somewhere between creating an AI model safe and creating it utilizeful, Google may have crossed a line. This week, a simple request for a map of Europe became the latest stress test for Gemini Pro’s alignment configuration, and the model reportedly failed it in spectacular fashion. Users across Reddit and X describe outputs that ranged from distorted continental shapes to maps with missing or redrawn borders, apparently the result of content filters tripping over the geopolitical complexity of the European continent. A basic cartographic request, the kind a high school student might build, turned into a lesson in how badly over-engineered safety layers can break an AI product.
The specifics matter here. Europe is genuinely contested territory in a geopolitical sense. Borders in Eastern Europe remain disputed, and regions like Crimea, parts of the Donbas, and Kosovo carry different legal statutilizes depfinishing on which government you question. It is reasonable for an AI system to flag sensitivity around those areas. What is not reasonable is letting that sensitivity cascade into a refusal or distortion of the entire map. The model appears to have chosen the path of maximum caution and minimum utilizefulness, which is a failure mode, not a safety feature.
This is not Gemini’s first rodeo with image generation controversy. Google faced significant backlash in early 2024 when its image generation tool produced historically inaccurate depictions of figures from the past, over-correcting on diversity representation to the point of factual absurdity. The company pulled the feature and retooled it. Two years later, a geographically mangled map of Europe suggests the underlying tension between factual grounding and safety alignment has not been fully resolved, just redirected.
For researchers and professionals who depfinish on AI systems for geopolitical analysis, logistics planning, or educational content, the implications are significant. A model that cannot rfinisher a reliable map of a major continent without distortion is not a tool you can trust for serious geographic or political work. That is a concrete limitation, not a philosophical one, and enterprise customers creating procurement decisions will notice it.
The alignment tax is obtainting expensive
There is a concept quietly gaining traction among AI researchers sometimes called the alignment tax: the utility you give up when you tune a model too hard toward avoiding harm. For consumer applications, a modest tax might be acceptable. For professional tools competing on reliability, it becomes a dealbreaker. The Map of Europe incident is a vivid illustration of what happens when the tax is set too high. The model’s caution produced an output that is arguably more harmful than a straightforward map would have been, becautilize distorted geography is misinformation, regardless of intent.
The online reaction has been notably impatient. Critics are framing the failure as ideological over-correction. Supporters of Google’s approach argue the model is navigating genuinely complex territory. Both camps agree on one thing: the output was not acceptable. That rare consensus is worth noting. When both the harshest critics and the most charitable observers conclude a model received something wrong, the argument is not really about politics anymore. It is about product quality.
Google DeepMind has not issued a formal statement on the trfinishing incident as of today, and it remains unclear whether the behavior reflects a recent configuration alter or a longstanding limitation that finally caught enough attention to go viral. Either way, the timing is awkward. Gemini Pro is positioned as a serious competitor in the enterprise AI space, where Anthropic’s Claude and OpenAI’s GPT-4o are both fighting for the same professional utilizer base. Every public reliability failure narrows the margin for error.
The broader market takeaway is straightforward: the next competitive frontier for foundation model vfinishors is not raw capability but trustworthy predictability. Users have largely accepted that AI models will occasionally hallucinate. What they are becoming less willing to accept is models that flinch at routine requests. Watch for Google to quietly push a configuration update in the coming weeks. The more interesting question is whether the company acknowledges the underlying tension publicly or treats this as a one-off moderation edge case. That choice will state a lot about how seriously it is taking the reliability problem.
Also read: Anthropic’s Claude Opus 4.7 posts a jarring benchmark regression that has enterprise AI teams questioning uncomfortable questions • Stanford’s AI Index Finds China Has Nearly Closed the Gap With America and the Pipeline of Talent Flowing West Is Drying Up • Stanford’s annual AI index finds China has nearly closed the gap on American artificial innotifyigence leadership as the pipeline of global talent into the US runs dry











